
有一些人,遇到一个问题时就想:“我知道,我会使用正则表达式。” 然后他就有两个问题了。
–by Jamie Zawinski
前些天优化一个 API 的时候,我在代码中发现一个正则就在群里随便乱吐槽了几句。然后leader就突然兴起让我给团队内来一场正则表达式的分享。对了,我吐槽的这个正则长这样:
1 | ^[a-z]([a-z0-9]*[-_\.]?[a-z0-9]+)*@([a-z0-9]*[-_]?[a-z0-9]+)+[\.][a-z]{2,3}([\.][a-z]{2})?$ |
当时我只说写这么长且无用的正则,简直了….
- 各位知道这个正则是做什么的么?
- 各位知道当匹配
[email protected]这种会有多少次回溯么?
序
文本处理工具,大家想到的绝对会有正则表达式(Regular Expressions)这个大佬,在当今的编程语言中,也找不出几个不支持正则的(有,当然有,比如 brainfuck) ,我周围的程序员也没有没接触过正则的。不过,接触了不代表就懂正则了。
“我也不知道它是怎么工作的,反正跑起来正常就行了”
–by 匿名用户
其实,正则表达式并没有那么那么的晦涩难懂,高大上,它不过是一个普通的 DSL 罢了,复杂的文本处理,也不应该用正则,而应该考虑比如 flex/bison 这种 parser 了。
正则基础
什么是正则表达式?
Regular Expression,简称 RE/Regex。用于匹配字符串中字符组合的模式。我们可以通过认识集合中有限的字符(正则表达式中的元字符)来识别属于这种集合的任意多的其他字符。
这样来讲,其实你之前已经接触过正则了,只是你不知道而已。比如:
- Ctrl + F
字符串子串匹配问题, 本质上也是正则。 - echo “shellvon” | grep von
我们在命令行下经常使用的 grep,其实你的von也算正则了
…
可是当我们要匹配的都是数字或者都是字母的时候。或者100个相同字母的时候,写起来就啰嗦复杂了。也谈不上模式!所以呢,我们引入了一种这样功能的字符: 自己不代表自己原本含义,而都有特殊含义的字符。比如,我希望点号 .可以匹配任意字符,具有这种功能的字符,我们称之为 元字符(metacharacters)
元字符
生活中,我们也早已经接触过所谓的元字符了。比如:
- 互联网脏话 -> 用
*给替代了 - 二胖Plus、鑫胖、金三月半、鑫月半、金三肥 -> 真实含义代表啥大家也知道
…
正则表达式里面有许多这样的元字符,这些元字符构成一个有限子集,让我们可以利用这个有限子集去识别和匹配无限可能的文本。
| 元字符 | 含义 |
|---|---|
| ^和$ | 行的开始^和结束$ |
| []和[^] | 字符组[]和排除型[^] |
| - | 连字符,必须出现在字符组内,表示范围比如[0-9] |
| . | 匹配任意字符(可能会排除\n哦) |
| *和+ | 量词,匹配该字符之前的字符,*是>=0次,+是>=1次 |
| {n}和{n,}和{n,m} | 区间量词,匹配次数{n}匹配n次,{n,m}匹配n~m次 |
| | | 或者 |
| ? | 量词,标记?前的字符为可选 |
| () | 字符集,标记完全匹配括号内的数据 |
| \ | 转义,用于匹配一些保留字符(比如元字符) |
如上表,这些字符出现在正则里面的时候,通常都不代表本来的含义。关于上表,还有几点需要注意:
- 脱字符
^必须出现在文本开头,美元符$必须出现在行尾 - 排除形里面也出现了脱字符
^,代表排除时也必须出现在中括号[]内的第一个字符,否则不具有此含义。 - 连字符,顾名思义,必须具有起止字符,否则就是自己本来的意思。比如[-]代表匹配自己,特殊一点的是[a-c-d]由于a-c已经表示了范围,后面的
-就找不到开始范围,那么第二个-就代表自己,所以匹配的是abc-d这5个字符。
我们来看元字符的一些例子:1
2
3
4
5
6
7
8
9"[Tt]he" => The car parked in the garage
^^^ ^^^
"[^c]ar" => The car parked in the garage
^^^ ^^^
"c.+t" => The fat cat sat on the mat
^^^^^^^^^^^^^^^^^^
¦----被(.+)匹配-¦
"b.g" => baidugoogle big bug bag
^^^ ^^^ ^^^
如你所见,我们正则的表达式匹配流程会是从左边往右边挨个来,就像你读本文如此。
这些元字符可不简单,万丈高楼也是靠它们。
子表达式
在算法领域有个很好的思想叫做 分治法 。当我们遇到一个复杂的需求,我们总是可以拆解成无数个小的问题,然后尝试去解决小问题,最后这些小问题的答案来解决大问题。正则表达式亦是如此。
一个复杂的正则表达式都是由一些简单的正则表达式组合起来的。这些简单的正则我们称之为 子表达式 。它们通常是指用 | 分割的多选分支或者括号内的表达式。
比如gr(e|a)y。我们可以将(e|a)看成子表达式,其中e和a也可以看成子表达式,严格意义上讲,上述的g/r/y等也算子表达式。不过这样太细了意义也不大。我们主要还是关注竖线|分割和括号()包围起来的更有意思。
首先,考虑这样一个问题:
如果需要让你用刚学的元字符去匹配一个0-23的范围的数字(比如时间刚好这个范围)怎么办?哦,天啦,你可能会说[0-23] 刚好啊,因为-可以表示范围,很遗憾,并不行,通常-能表示的开始和结束都只有一个字符(虽然16进制这种就不是了),但是你要知道,上述表达式的真实含义是匹配[0123]这四个数字。
这个可以参见我前文提到的关于连字符-的注意事项。这种方式不可行,另外一个最容易想到的就是拆分它,我们可以利用子表达式这个概念。
怎么拆呢?
1. `[0-9]` 可以匹配范围个位数
2. `1[0-9]` 可以匹配10-19的
3. `2[0-3]` 可以匹配20-23的
显然,最后用元字符|(代表或)将他们连接起来就符合要求了撒。
如果更加复杂一点呢,比如要匹配一个 IPv4 地址呢?其实原理一样,只是数字范围变成了0-255。这正如文章开头的图中所示。
更为复杂的就是,考虑匹配一个日期,需要考虑月份和天数的关系,甚至还有闰年(通常这种时候你还要用正则的话,你估计已经开始过度使用正则了,你需要避免这样)
简写
懒惰是程序员的美德之一。在上面的例子中我们写[0-9]要写5个字符,有没有更简写的呢?
| 简写字符 | 含义 |
|---|---|
| . | 匹配任意字符 |
| \d和\D | \d表示数字,\D非数字 |
| \w和\W | \w等效于[a-zA-Z0-9_],\W相反 |
| \s和\S | \s匹配所有空格字符,\S相反 |
举个例子:1
2
3
4
5
6"\d{2,3}" => The number was 9.9997.
^^^
"car\sis" => The car is parked.
^^^^^^
"^\d+" => 13 is less than 18.
^^
捕获,非捕获与反向引用
目前为止,我们知道括号可以用在子表达式中,表示完整的一个整体。括号另外还有一个作用是 捕获 。所谓捕获,就是指正则引擎(正则的大脑)可以记住匹配的结果,会给这些结果取一个小名,用于之后的用途,取名规则是这样的:
每个括号从左向右以左括号为标志,会自动拥有一个组号,从1开始。
比如: (hello (world (regex)))
分组如下:
1. hello world regex <-- 第一个组,组号为1,后面以此类推
2. world regex <-- 第二个组
3. regex <-- 第三个组,因为左括号出现的比较晚
这样有个好处,我们可以在正则里面通过组号拿之前匹配的结果,这种方式叫做 反向引用 。
举个例子:1
2
3“([ab])\1” => abcdebbcde
^^
¦-----这个`b`就是因为前面的([ab])匹配到了一个字符b。我们可以用\1来引用起之前结果
显然,有时候我们并不需要捕获(不然数字一直在增大的同时,让正则脑袋记那么多内容,效率也不好),所以与之对应的还有 非捕获。写法很相似:(?:pattern)。一个更具体的对比表如下:
| 语法 | 含义 | 例子 |
|---|---|---|
| (pattern) | 匹配pattern并捕获结果,自动设置组号 | (\d{2})+\d |
| (?:pattern) | 匹配pattern,但是不捕获 hell(?:o|y) | 匹配hello/helly |
显然,如果一个复杂的表达式里面引入过多的非捕获,虽然可以减少正则引擎去记忆,但是这也会增加我们阅读正则表达式的难度,所以,请深思熟虑是否有必要为了这么一点性能而用非捕获。
另一方面,在复杂的正则表达式中如果全部使用了捕获,试想一下这种情况:
有天你突然把某个括号删除了,或者需要在中间某处增加一个括号,会产生什么样的影响?
聪明的你应该想到了,会导致组号的变更。比如原来是\3,现在可能变成了\2或者\4,或者其他。
所以捕获如果按照数字取名字实在不是很好。于是写 Python 正则的那群人说,要不给这些组取名字的事情交给用户吧,比如叫张三,李四。这种技术叫做
命名捕获。大概是这么写的(?P<myname>hello) 它不仅具有原来数字的乳名\1,还有用户你自己为它取的名字myname。这种方式很棒,.Net觉得不错也抄袭了过去,只不过语法不一样罢了。更多的细节请参见:
Named Capturing Groups and Backreferences
正则进阶
之前基础部分已经可以完成日常简单的需求了,甚至我们仔细想想可以知道正则最重要的两点原则:
- 匹配先从需要查找的字符串的起始位置尝试匹配,是从左至右的。
- 总是尝试匹配尽可能多的字符,我们称之为贪婪。
第一点:
比如”Python”匹配 “i am Pythoner, i love Python.”; 正则匹配到 _Python_er, 而不是后面的 Python 。因为他是左边开始的,先找到谁就是谁。
第二点: 贪婪(Greedy),我们的所有量词都是尽可能多的匹配!
贪婪与非贪婪
还记得这个例子么?1
2
3"c.+t" => The fat cat sat on the mat
^^^^^^^^^^^^^^^^^^
¦----被(.+)匹配-¦
我们来描述一下这个流程:
- 正则表达式的
c开始不能匹配’T’,直到遇到单词’cat’中的’c’,于是宣告’c’匹配成功。开始尝试.来匹配后续 - 正则表达式中的
.开始匹配单词’cat’中的’.’,发现还是可以匹配。 - 有趣的事情来了: 正则发现.后面有个+,即告诉我吃至少一个,那么我怎么抉择呢?答案是:我尽可能吃撑,吃到吃不下去为止–这就是贪婪。
- 于是.继续匹配,一路所向披靡,因为.啥字符都可以吃啊,然后走到了最后,单词’mat’中’t’的后面为止。发现没有匹配了,点号吃不下去了,就该让表达式
c.+t中的t上场,发现t也不行,怎么办呢?难道宣告正则匹配失败??不不不,毕竟+表示的1到多嘛,我可以通知.吐一个字符出来,让t试试呢 - 于是.就吐出来了’t’,记住这时候
.+已经吃下了’at sat on the ma’这么多字符。 - 这时候发现
t可以匹配’mat’中的’t’.这时候文本也是结束了,正则引擎宣告匹配成功!
这就是贪婪,.+企图吃掉所有字符,可惜最后匹配失败,它很不情愿的吐出了最后一个字符’t’,然后才让正则匹配成功的。
试想,如果.+不贪婪,很谦虚,那么我可以只吃一个字符’a’,让t取匹配’cat’中’t’.结果也会成功。但是却贪婪了。。贪婪与否会严重影响正则匹配的结果
所以用户可能会问了:
我怎么告诉正则引擎不贪婪呢?
我怎么告诉正则引擎如果我贪婪了,我也不想吐出来呢?(比贪婪还贪婪)
这其实都很简单:
在原来标准量词的后面加一个问号,即为忽略优先量词
在原来标准量词的后面加一个加号,即为占有优先量词
| 语法 | 含义 |
|---|---|
| 忽略优先 | *?,+? ,?? ,{n,m}? |
| 占有优先 | *+,++,?+,{n,m}+ |
我们看一下这个例子:1
2
3
4
5
6
7
8
9
10
11".*shell" => shellxxxxxshell
^^^^^^^^^^^^^^^
¦----- 之前的shellxxxxx都被.*吃了,这种情况参见上一个关于贪婪的描述
".*?shell" => shellxxxxxshell
^^^^^
¦---.*什么都不要,因为?告诉它忽略优先
".*+shell" => shellxxxxxshell
什么都匹配不到,因为.*已经可以贪婪的吃掉整句话,有了+表示占有优先,吃了是不会吐出来的,
所以啥都吃完了,也没有字符留给正则里面的shell来匹配了。导致整个匹配都会失败
调试
这个可能是最重要的一个环节。
工欲善其事,必先利其器。调试正则的话,也需要一个特别好的工具,我这里推荐在线的工具:
https://regex101.com/
一两句无法说清,所以试图以图的形式简单介绍一下。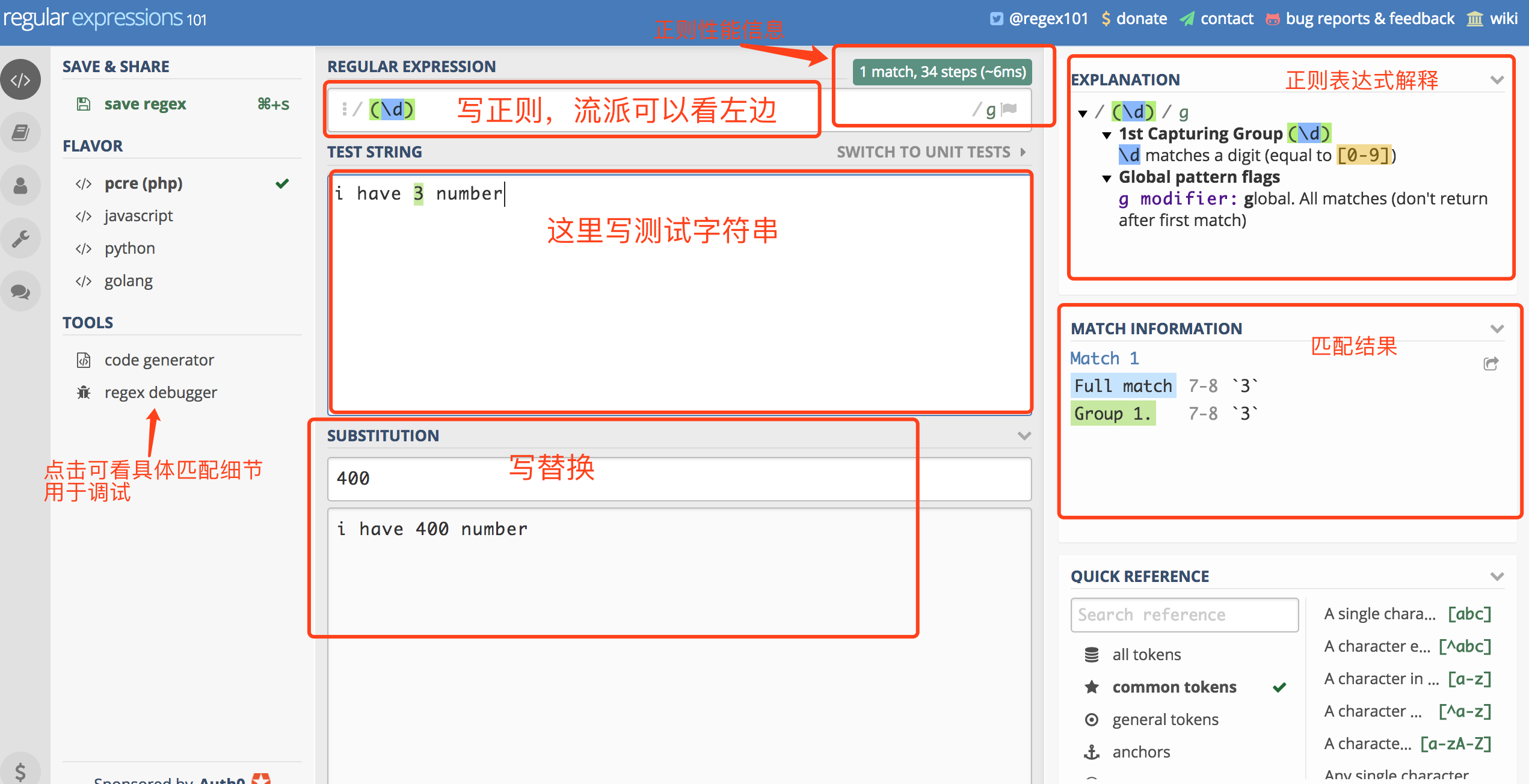
具体学习,还是请以 Learn by Practice 为准。而不是 Learn by manual。
环视
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(使用[^])。但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?
这时候我们需要查找它所在的位置!正则表达式里面匹配位置的在我们之前接触过的有^和$,前者是开始,后者是结束。
| 语法 | 匹配条件 | 例子 |
|---|---|---|
| (?<=…) | 子表达式能匹配左侧文本 | (?<=[a-z])[A-Z] |
| (?<!…) | 子表达式不能匹配左侧文本 | |
| (?=…) | 子表达式能匹配右侧文本 | (?=[a-z])[A-Z] |
| (?!…) | 子表达式不能匹配右侧文本 | \d{3}(?!\d) |
具体位置的举例如下:
1 | (?=\d) (?<=\d) |
环视功能可以做很多有趣的事情:
比如匹配标签: (?<=<(\w{3})>).*(?=<\/\1>)
比如判断密码的强度:
1 | ^(?=.*[0-9]) <-- 右侧必须有数字 |
其他特性
正则里面有很多重要的特性,限于30分钟和篇幅原因,我无法都写上,我提一下一些概念,有兴趣的同学可以自行检索关键字。
- 正则表达式引擎(流派) 比如NFA/DFA.
- 递归的正则表达式
- 正则回溯
- 宽松模式
- 条件判断
- 正则本地化(locale) 以及Unicode
- 模式修饰符(re pattern modifiers)
参考资料
- 杂项 https://stackoverflow.com/a/22944075
- 书籍 Mastering Regular Expressions
- PCRE https://www.pcre.org/
- 手册 http://www.rexegg.com
- 手册 https://www.regular-expressions.info/
- man pcre (Mac/Linux下)
- 调试 https://regex101.com/
- 可视化 https://www.debuggex.com/
- PHP 项目 FastRoute (应用正则很好的例子)
- Python 项目 Bottle (应用正则很好的例子)
- Markdown Parser

